The key design goal that we had for the data storage layer is that the data on disk is stored in a consistent, well described manner and is not dependent on the existence of any service to navigate and understand it. Too often data projects separate the data from the metadata (data on disk, metadata in a database) and if the service fails, are left with a disk full of data that is not described. Though there are ways to mitigate this (database backups), this model still requires significant effort to ‘rebuild’ the complete view of the data by joining the on disk representation with the metadata in the database. We base our metadata on the Open Language Archives Community (OLAC) rather than the European CMDI standard as we found CMDI too detailed, and we want to encourage users to fill out as much metadata as possible without adding a hurdle of complexity.
Given this, and decades of prior experience operating the PARADISEC catalog, we made the decision at the very beginning of the project to design our storage layer so that it was a complete representation of the data that could stand alone from the workspace service.
To support this goal we settled on describing our data objects as Research Object Crates (RO Crate). The RO Crate specification is a method for aggregating and describing research data with associated metadata. Specifically, the metadata is described using schema.org definitions (mostly, with specific extensions) stored as a JSON linked data file inside the folder containing the data objects themselves.
One of the nice aspects of this specification is that the metadata is written as JSON rather than XML. JSON as a format is more easily worked with in modern software environments than XML. It does not require specific XML skills (XSLT experts) to work with; and is generally readable by users even though it’s a machine data interchange format.
Metadata descriptions: Describo
For the metadata description, the workspace uses the Describo suite of tools and service. The main component is a VueJS plugin that can be embedded into an application to manage the metadata creation for an object. The design is such that the application is responsible for loading / saving the metadata that the component manages internally to itself. The Describo interface is constructed from a profile that is provided to the application and is typically written by a domain expert. It defines the classes and properties that users can describe and the UI is constructed from that definition (Describo is no longer developed and the current RO-Crate editing tool is Crate-O).
Note that all material is held on servers in Australia and that no AI is trained on any material in Nyingarn. We use Amazon’s Textract for OCR and have opted out of their use of any items in this workspace for AI training.
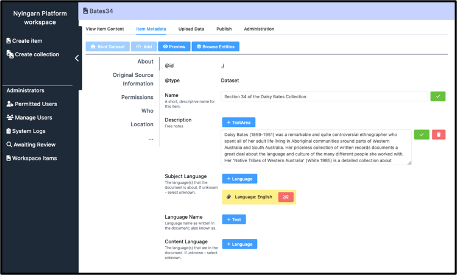
The screenshot shows the Describo tool. In it we can see that there are some groups defined down the left (About, Original Source Information etc) and then properties with data on the right. The layout (groups and properties shown on each tab) are all defined in the profile so an application can adapt its metadata editor exactly as it needs.
The repository and interface
Once an item has been transcribed, the user can nominate it to be published to the repository. As we are working with Indigenous language materials, permission from a relevant language authority is required before the item can be published. We also require permission from the copyright holder or equivalent. Both of these are provided on forms which accompany items in the repository. If it is not appropriate for an item to move to the repository with either restricted or open access, the transcription should be downloaded and the item deleted from the workspace.
The repository will permit searching over all text, and will include fuzzy searching, allowing for the range of variation expected in early writing of Australian Indigenous languages. For example, an Italian observer writes the palatal nasal as ‘gn’, while an English observer may use ‘ny’, or ‘ni’. Each of these options is provided in a fuzzy search, allowing more generous search results than would a literal string. Items can be recalled to the workspace from the repository if necessary for editing or addition of new information. We also want to allow a synonym search, so, for example, searches for ‘porcupine’ will also find ‘echidna’.
Code, Licensing, Principles
All code is released with the GPLv3 license and is available from the CoEDL GitHub organisation.
As much as possible existing tools and services will be integrated with development focused on providing a coherent user experience around those services. As much as possible tools and processes will be modular and containerised in order to support reproducibility in deployment and ease of use by others.
A major principle of our work is conforming to the same principles promoted by the Australian Research Data Commons and the Language Data Commons of Australia.