Nyingarn Community Workshops – Please contact us for training and workshops in your community. Workshops we have delivered in the past have been in-person half-day or full-day of training, or online. Contact the Nyingarn Team, via nyingarn-project@unimelb.edu.au for more information.
Spinning a Better Yarn – The Nyingarn Project: Reawakening Language Archives
Gari Tudor-Smith (Baradha, Yiman, Gureng Gureng, Gangulu), Thomas Watson (Gangulu, Yiman, Garingbal, Gureng Gureng) and Paul Williams (Gamilaraay). The University of Melbourne and The University of Queensland.
Language Manuscripts in Archives presentation at the Language Documentation and Archiving Conference 2023.
Nick Thieberger, Marco La Rosa and Sophie Lewincamp, University of Melbourne.
Nick Thieberger, Sophie Lewincamp, Marco La Rosa. 2024. “Nyingarn: Supporting Australian Indigenous languages from textual sources,” In Proceedings of the 3rd Conference on Digital Preservation and Processing Technology of Written Heritage, Agadir, December 2023 2023 7th IEEE Congress on Information Science and Technology (CiSt), Agadir – Essaouira, Morocco, 2023, pp. 575-580, doi: 10.1109/CiSt56084.2023.10409913. Available here
Maya kora koorliny (language comeback): Access and arts in Australia. Bracknell, C., Nov 2023, In: Living Languages. 2, 1, p. 310 331
Nyingarn Timeline
October 2022 – We launch a Nyingarn Project poster illustrated by Allyra Murray.
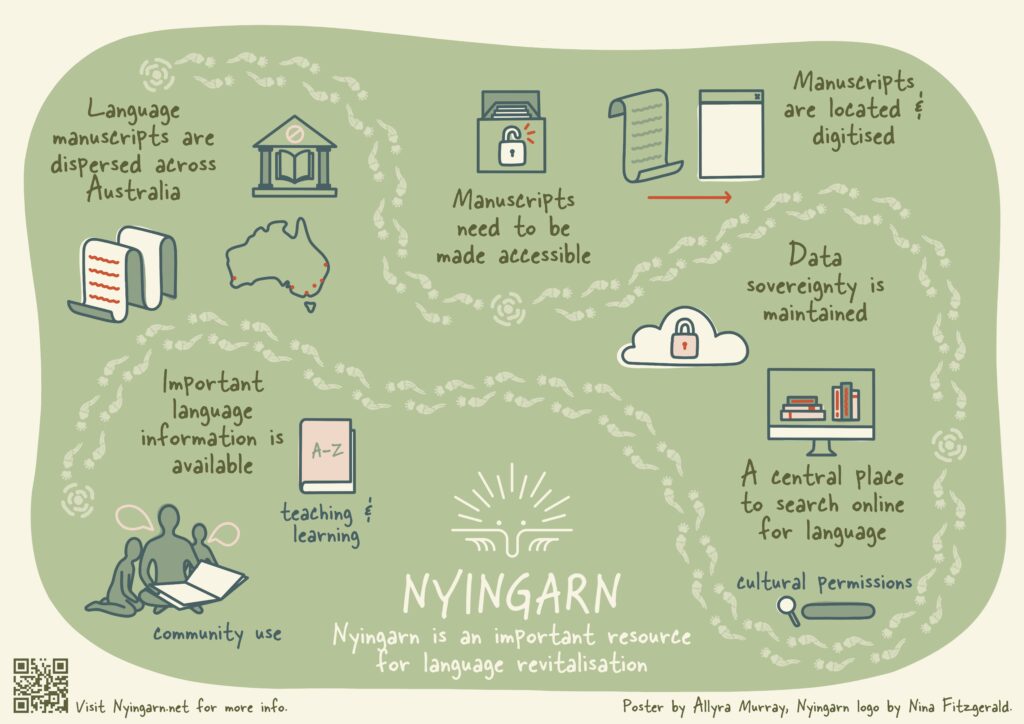
Early manuscripts containing wordlists and language information. These manuscripts are dispersed across Australia and often off-country. Being far away from the communities presents several challenges. Community access to their information is one such challenge. Manuscripts are also written in cursive handwriting, which can be difficult to read. The Nyingarn project is working to locate and access these manuscripts. Following protocols developed in line with community wishes, manuscript images are transcribed, converted into text format, and stored in one place. This process makes manuscripts searchable, more ‘user-friendly and more easily accessible to communities. Nyingarn is an important resource for language revitalisation, maintenance and sustainability.
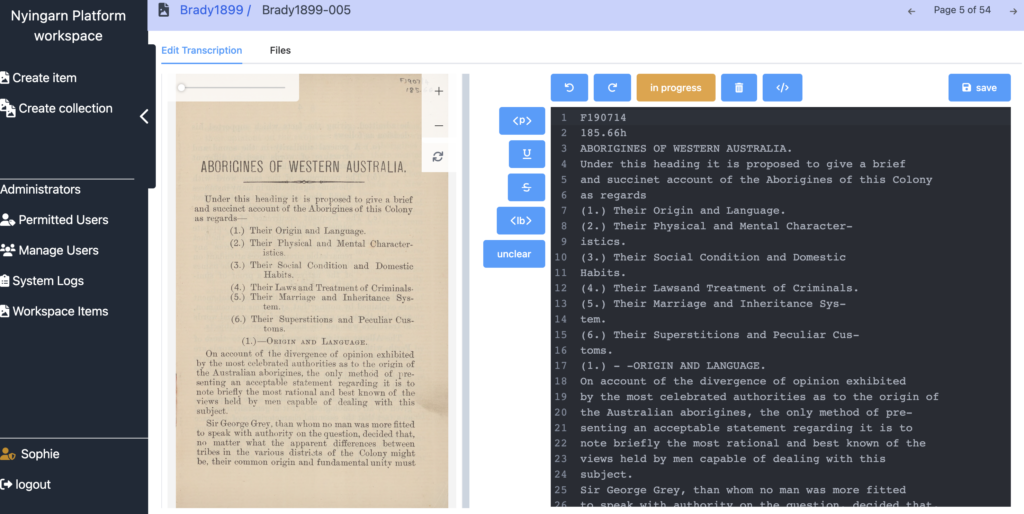
July 2022 – Our team continues to test the Nyingarn Workspace. We can ingest manuscript images for automated optical character recognition (OCR), and to join manuscript images to their corresponding transcriptions created in DigiVol or FromthePage. The image below shows the Nyingarn Workspace user view: manuscript image on the left and transcription text on the right.
Our latest work allows existing manuscript transcriptions in word format by our CIs to be converted into tei.xml and added to the Workspace. The Nyingarn Project is working with communities and our partner institutions to gather early language manuscripts and make them accessible in one place.
March 2022 – The Nyingarn Platform workspace has been built, and the Project Team are now testing ways to convert images of manuscripts to text using either Optical Character Recognition (OCR) or crowdsourced transcription platforms. We have tested two OCR systems with differing results for typed and hand-written manuscripts.
Manuscripts with existing permissions have also been transcribed through the online crowdsourcing platform, DigiVol, hosted by the Australian Museum. We have created manuscript transcription ‘expeditions’ in DigiVol, allowing us to refine transcribing guides for volunteers and then export this language data into our workspace. To date, expeditions of 20-40 pages have been transcribed by volunteers within days. At Nyingarn, we will continue refining these transcription techniques as more manuscripts in state and national institutions are identified by CIs and Steering Committee members.
Registered users can access the workspace.